
In the previous section we discussed standard transformations of the Cartesian plane – rotations, reflections, etc. As a motivational example for this section’s study, let’s consider another transformation – let’s find the matrix that moves the unit square one unit to the right (see Figure \(\PageIndex\)). This is called a translation.
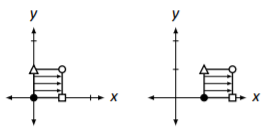
Figure \(\PageIndex\): Translating the unit square one unit to the right.
Our work from the previous section allows us to find the matrix quickly. By looking at the picture, it is easy to see that \(\vec>\) is moved to \(\left[\begin\\\end\right]\) and \(\vec
However, look at Figure \(\PageIndex\) where the unit square is drawn after being transformed by \(A\). It is clear that we did not get the desired result; the unit square was not translated, but rather stretched/sheared in some way.
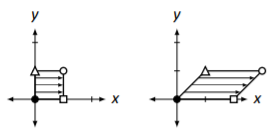
Figure \(\PageIndex\): Actual transformation of the unit square by matrix \(A\).
What did we do wrong? We will answer this question, but first we need to develop a few thoughts and vocabulary terms.
We’ve been using the term “transformation” to describe how we’ve changed vectors. In fact, “transformation” is synonymous to “function.” We are used to functions like \(f(x) = x^2\) , where the input is a number and the output is another number. In the previous section, we learned about transformations (functions) where the input was a vector and the output was another vector. If \(A\) is a “transformation matrix,” then we could create a function of the form \(T(\vec)=A\vec\). That is, a vector \(\vec\) is the input, and the output is \(\vec\) multiplied by \(A\).\(^\)
When we defined \(f(x) = x^2\) above, we let the reader assume that the input was indeed a number. If we wanted to be complete, we should have stated \[f:\mathbb \to\mathbb \quad \text < where >\quad f(x)=x^2.\nonumber \] The first part of that line told us that the input was a real number (that was the first \(\mathbb\)) and the output was also a real number (the second \(\mathbb\)).
To define a transformation where a 2D vector is transformed into another 2D vector via multiplication by a \(2\times 2\) matrix \(A\), we should write
Here, the first \(\mathbb^\) means that we are using 2D vectors as our input, and the second \(\mathbb^\) means that a 2D vector is the output.
Consider a quick example:
Notice that this takes 2D vectors as input and returns 3D vectors as output. For instance,
We now define a special type of transformation (function).
A transformation \(T:\mathbb^\to\mathbb^\) is a linear transformation if it satisfies the following two properties:
If \(T\) is a linear transformation, it is often said that “\(T\) is linear.”
Let’s learn about this definition through some examples.
Determine whether or not the transformation \(T:\mathbb^\to\mathbb^\) is a linear transformation, where
Solution
We’ll arbitrarily pick two vectors \(\vec\) and \(\vec\):
Let’s check to see if \(T\) is linear by using the definition.
Therefore, \(T\) is not a linear transformation.
So we have an example of something that doesn’t work. Let’s try an example where things do work.\(^\)
Determine whether or not the transformation \(T\) : \(\mathbb^\to\mathbb^\) is a linear transformation, where \(T(\vec)=A\vec\) and
Solution
Let’s start by again considering arbitrary \(\vec\) and \(\vec\). Let’s choose the same \(\vec\) and \(\vec\) from Example \(\PageIndex\).
If the lineararity properties hold for these vectors, then maybe it is actually linear (and we’ll do more work).
We have seen two examples of transformations so far, one which was not linear and one that was. One might wonder “Why is linearity important?”, which we’ll address shortly.
First, consider how we proved the transformation in Example \(\PageIndex\) was linear. We defined \(T\) by matrix multiplication, that is, \(T(\vec) = A\vec\) . We proved \(T\) was linear using properties of matrix multiplication – we never considered the specific values of \(A\)! That is, we didn’t just choose a good matrix for \(T\) ; any matrix \(A\) would have worked. This leads us to an important theorem. The first part we have essentially just proved; the second part we won’t prove, although its truth is very powerful.
The second part of the theorem says that all linear transformations can be described using matrix multiplication. Given any linear transformation, there is a matrix that completely defines that transformation. This important matrix gets its own name.
Let \(T\): \(\mathbb^\to\mathbb^\) be a linear transformaton. By Theorem \(\PageIndex\), there is a matrix \(A\) such that \(T(\vec)=A\vec\). This matrix \(A\) is called the standard matrix of the linear transformation \(T\), and is denoted \([ T ]\).\(^\)
[a] The matrix–like brackets around \(T\) suggest that the standard matrix \(A\) is a matrix “with \(T\) inside.”
While exploring all of the ramifications of Theorem \(\PageIndex\) is outside the scope of this text, let it suffice to say that since 1) linear transformations are very, very important in economics, science, engineering and mathematics, and 2) the theory of matrices is well developed and easy to implement by hand and on computers, then 3) it is great news that these two concepts go hand in hand.
We have already used the second part of this theorem in a small way. In the previous section we looked at transformations graphically and found the matrices that produced them. At the time, we didn’t realize that these transformations were linear, but indeed they were.
This brings us back to the motivating example with which we started this section. We tried to find the matrix that translated the unit square one unit to the right. Our attempt failed, and we have yet to determine why. Given our link between matrices and linear transformations, the answer is likely “the translation transformation is not a linear transformation.” While that is a true statement, it doesn’t really explain things all that well. Is there some way we could have recognized that this transformation wasn’t linear?\(^\)
Yes, there is. Consider the second part of the linear transformation definition. It states that \(T(k\vec) = kT(\vec)\) for all scalars \(k\) . If we let \(k=0\) , we have \(T(0\vec) = 0\cdot T(\vec)\) , or more simply, \(T(\vec) =\vec\) . That is, if \(T\) is to be a linear transformation, it must send the zero vector to the zero vector.
This is a quick way to see that the translation transformation fails to be linear. By shifting the unit square to the right one unit, the corner at the point \((0,0)\) was sent to the point \((1,0)\) , i.e.,
This property relating to \(\vec\) is important, so we highlight it here.
Let \(T\): \(\mathbb^\to\mathbb^\) be a linear transformation. Then:
That is, the zero vector in \(\mathbb^\) gets sent to the zero vector in \(\mathbb^\).
The interested reader may wish to read the footnote below.\(^\)
It is often the case that while one can describe a linear transformation, one doesn’t know what matrix performs that transformation (i.e., one doesn’t know the standard matrix of that linear transformation). How do we systematically find it? We’ll need a new definition.
In \(\mathbb^\), the standard unit vectors \(\vec>\) are the vectors with a \(1\) in the \(i^>\) entry and \(0\)s everywhere else.
We’ve already seen these vectors in the previous section. In \(\mathbb^\), we identified
In \(\mathbb^\), there are \(4\) standard unit vectors:
How do these vectors help us find the standard matrix of a linear transformation? Recall again our work in the previous section. There, we practiced looking at the transformed unit square and deducing the standard transformation matrix \(A\). We did this by making the first column of \(A\) the vector where \(\vec>\) ended up and making the second column of \(A\) the vector where \(\vec>\) ended up. One could represent this with:
That is, \(T(\vec>)\) is the vector where \(\vec>\) ends up, and \(T(\vec>)\) is the vector where \(\vec>\) ends up.
The same holds true in general. Given a linear transformation \(T:\mathbb^\to\mathbb^\), the standard matrix of \(T\) is the matrix whose \(i^\text\) column is the vector where \(\vec>\) ends up. While we won’t prove this is true, it is, and it is very useful. Therefore we’ll state it again as a theorem.
The Standard Matrix of a Linear Transformation
Let \(T\): \(\mathbb^\to\mathbb^\) be a linear transformation. Then \([T]\) is the \(m\times n\) matrix:
Let’s practice this theorem in an example.
Define \(T\): \(\mathbb^\to\mathbb^\) to be the linear transformation where
Solution
\(T\) takes vectors from \(\mathbb^\) into \(\mathbb^\), so \([\, T \, ]\) is going to be a \(4\times 3\) matrix. Note that
We find the columns of \([T]\) by finding where \(\vec>\), \(\vec>\) and \(\vec>\) are sent, that is, we find \(T(\vec>)\) , \(T(\vec>)\) and \(T(\vec>)\) .
Let’s check this. Consider the vector
Strictly from the original definition, we can compute that
Now compute \(T(\vec)\) by computing \([T]\vec=A\vec\).
Let’s do another example, one that is more application oriented.
A baseball team manager has collected basic data concerning his hitters. He has the number of singles, doubles, triples, and home runs they have hit over the past year. For each player, he wants two more pieces of information: the total number of hits and the total number of bases.
Using the techniques developed in this section, devise a method for the manager to accomplish his goal.
Solution
If the manager only wants to compute this for a few players, then he could do it by hand fairly easily. After all:
However, if he has a lot of players to do this for, he would likely want a way to automate the work. One way of approaching the problem starts with recognizing that he wants to input four numbers into a function (i.e., the number of singles, doubles, etc.) and he wants two numbers as output (i.e., number of hits and bases). Thus he wants a transformation \(T\): \(\mathbb^\to\mathbb^\) where each vector in \(\mathbb^\) can be interpreted as
and each vector in \(\mathbb^\) can be interpreted as
(What do these calculations mean? For example, finding \(T(\vec>) = \left[\begin\\\end\right]\) means that one triple counts as \(1\) hit and \(3\) bases.)
Thus our transformation matrix \([T]\) is
As an example, consider a player who had \(102\) singles, \(30\) doubles, \(8\) triples and \(14\) home runs. By using \(A\), we find that
meaning the player had \(154\) hits and \(242\) total bases.
A question that we should ask concerning the previous example is “How do we know that the function the manager used was actually a linear transformation? After all, we were wrong before – the translation example at the beginning of this section had us fooled at first.”
This is a good point; the answer is fairly easy. Recall from Example \(\PageIndex\) the transformation
and from Example \(\PageIndex\)
where we use the subscripts for \(T\) to remind us which example they came from.
We found that \(T_\) was not a linear transformation, but stated that \(T_\) was (although we didn’t prove this). What made the difference?
Look at the entries of \(T_(\vec)\) and \(T_(\vec)\). \(T_\) contains entries where a variable is squared and where \(2\) variables are multiplied together – these prevent \(T_\) from being linear. On the other hand, the entries of \(T_\) are all of the form \(a_1x_1 + \cdots + a_nx_n\) ; that is, they are just sums of the variables multiplied by coefficients. \(T\) is linear if and only if the entries of \(T(\vec)\) are of this form. (Hence linear transformations are related to linear equations, as defined in Section 1.1.) This idea is important.
Let \(T\): \(\mathbb^\to\mathbb^\) be a transformation and consider the entries of
\(T\) is linear if and only if each entry of \(T(\vec)\) is of the form \(a_x_+a_x_+\cdots a_x_.\)
Going back to our baseball example, the manager could have defined his transformation as
Since that fits the model shown in Key Idea \(\PageIndex\), the transformation \(T\) is indeed linear and hence we can find a matrix \([T]\) that represents it.
Let’s practice this concept further in an example.
Using Key Idea \(\PageIndex\), determine whether or not each of the following transformations is linear.
Solution
\(T_1\) is not linear! This may come as a surprise, but we are not allowed to add constants to the variables. By thinking about this, we can see that this transformation is trying to accomplish the translation that got us started in this section – it adds \(1\) to all the \(x\) values and leaves the \(y\) values alone, shifting everything to the right one unit. However, this is not linear; again, notice how \(\vec\) does not get mapped to \(\vec\).
\(T_2\) is also not linear. We cannot divide variables, nor can we put variables inside the square root function (among other other things; again, see Section 1.1). This means that the baseball manager would not be able to use matrices to compute a batting average, which is (number of hits)/(number of at bats).
\(T_3\) is linear. Recall that \(\sqrt\) and \(\pi\) are just numbers, just coefficients.
We’ve mentioned before that we can draw vectors other than 2D vectors, although the more dimensions one adds, the harder it gets to understand. In the next section we’ll learn about graphing vectors in 3D – that is, how to draw on paper or a computer screen a 3D vector.
[1] We used \(T\) instead of \(f\) to define this function to help differentiate it from “regular” functions. “Normally” functions are defined using lower case letters when the input is a number; when the input is a vector, we use upper case letters.
[2] Recall a principle of logic: to show that something doesn’t work, we just need to show one case where it fails, which we did in Example \(\PageIndex\). To show that something always works, we need to show it works for all cases – simply showing it works for a few cases isn’t enough. However, doing so can be helpful in understanding the situation better.
[3] Recall that a vector is just a special type of matrix, so this theorem applies to matrix–vector multiplication as well.
[4] That is, apart from applying the definition directly?
[5] The idea that linear transformations “send zero to zero” has an interesting relation to terminology. The reader is likely familiar with functions like \(f(x) = 2x+3\) and would likely refer to this as a “linear function.” However, \(f(0) \neq 0\) , so \(f\) is not “linear” by our new definition of linear. We erroneously call \(f\) “linear” since its graph produces a line, though we should be careful to instead state that “the graph of \(f\) is a line.”
[6] Of course they do. That was the whole point.
This page titled 5.2: Properties of Linear Transformations is shared under a CC BY-NC 3.0 license and was authored, remixed, and/or curated by Gregory Hartman et al. via source content that was edited to the style and standards of the LibreTexts platform.